近日,CVPR 2023 论文接收结果出炉。近年来,CVPR 的投稿数量持续增加,今年收到有效投稿 9155 篇,和 CVPR 2022 相比增加 12%,创历史新高。最终,大会收录论文 2360 篇,接收率为 25.78 %。本次,旷视研究院有 13 篇论文入选,涵盖3D 目标检测、多目标跟踪、模型压缩、知识蒸馏等多个领域。以下为入选论文简介 :
👇
01
VoxelNeXt:Fully Sparse VoxelNet for 3D Object Detection and Tracking
用于3D检测和跟踪的纯稀疏体素网络
目前自动驾驶场景的3D检测框架大多依赖于dense head,而3D点云数据本身是稀疏的,这无疑是一种低效和浪费计算量的做法。我们提出了一种纯稀疏的3D 检测框架 VoxelNeXt。该方法可以直接从sparse CNNs 的 backbone网络输出的预测 sparse voxel 特征来预测3D物体,无需借助转换成anchor, center, voting等中间状态的媒介。该方法在取得检测速度优势的同时,还能很好地帮助多目标跟踪。VoxelNeXt在nuScenes LIDAR 多目标跟踪榜单上排名第一。
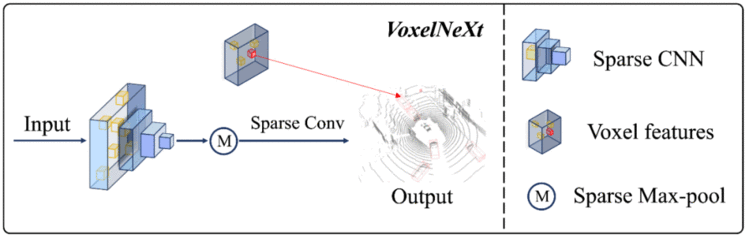
👉关键词:纯稀疏、nuScenes 3D点云多目标跟踪SOTA
https://arxiv.org/abs/2303.11301
02
A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
用于视频帧预测的多尺度动态体素流网络
根据现有的视频帧预测未来的视频帧是一个运动理解和表示学习中的重要任务。先进的深层神经网络极大地提高了视频预测的性能,然而大多数现有方法需要大模型和额外的输入(对应的分割图或者深度图)来预测未来帧。为了更高的效率和更广泛的应用,我们提出动态多尺度体素流网络(Dynamic Multi-scale Voxel Flow Network,DMVFN),DMVFN 仅需要图片帧输入,以相当低的计算成本实现了最先进的视频帧预测性能。DMVFN 的核心是一个可微分的路由模块,它可以有效地感知视频帧的运动规模,在推理阶段自适应地选择适当的子网络。DMVFN 的计算量只有经典的深度体素流方法 DVF 的三十分之一,并且在画面质量上超过了最新的基于迭代的 OPT 算法。
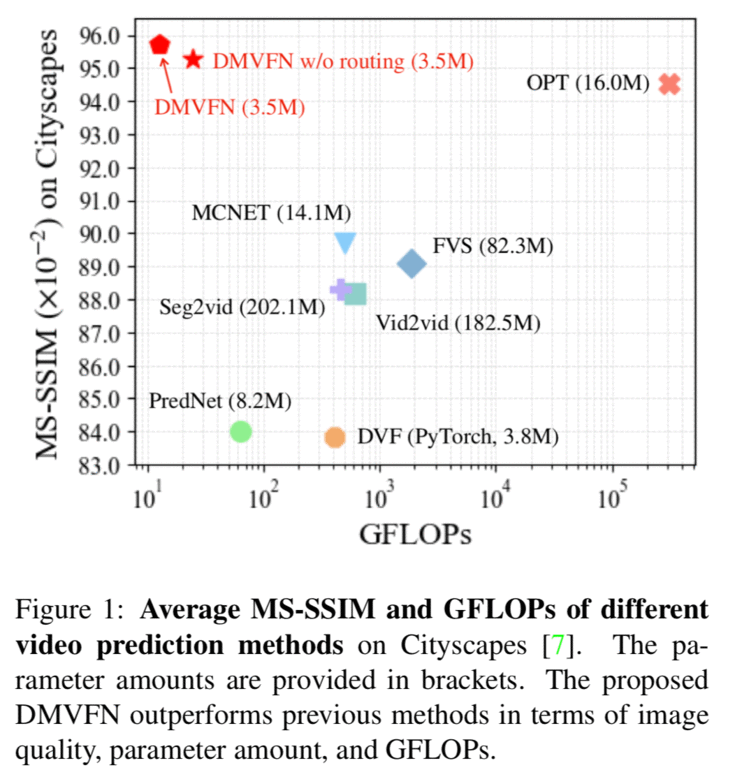
👉关键词:视频预测、动态网络、视频画质、光流
https://huxiaotaostasy.github.io/DMVFN/
03
Three Guidelines You Should Know for Universally Slimmable Self-Supervised Learning
用于指导通用可裁减的自监督学习的三个准则
自监督训练已经代替监督训练逐渐成为目前深度学习的主流, 但如何在面向不同计算资源的平台时部署自监督模型仍然是一个挑战. 为进一步高效部署预训练模型, 我们探索了自监督学习的预训练过程中如何令模型具备universally slimmable的性质, 使得模型可以在预训练过程结束后可以根据目标平台的资源限制选择最优的模型尺寸, 达到精度与效率之间更好的trade-off. 然而, 我们发现由于梯度的时序不一致性会导致直接将应用slimmable network应用到自监督中会导致训练崩溃. 为此, 我们提出三个指导准则用于设计损失函数来保证梯度的时序一致性. 另外, 为进一步提升精度和减少训练开销, 分别提出了group regularization和dynamic sampling的技术. 通过上述方式, 我们的方法US3L只需一次预训练且仅需一份完整模型权重就可以根据具体硬件限制裁减进行适配. US3L在不同的CV任务(分类, 检测, 分割)和不同的架构(CNN, ViT)都进行了验证均取得很好的效果。
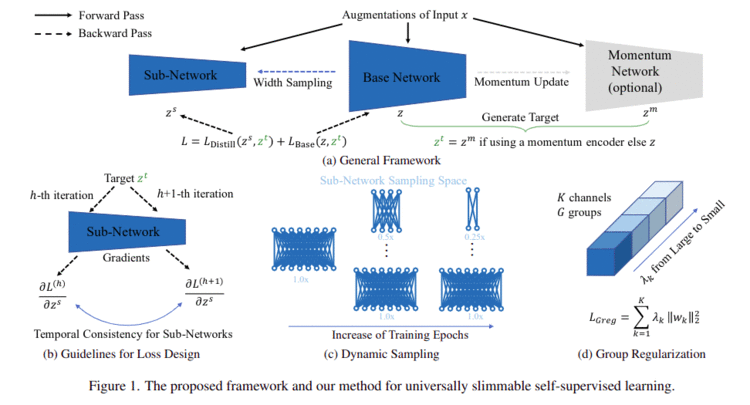
👉关键词: self-supervised learning, universally slimmable, temporal consistency, cnns, vit
https://arxiv.org/abs/2303.06870
04
MOTRv2: Bootstrapping End-to-End Multi-Object Tracking by Pretrained Object Detectors
利用预训练物体检测器大规模提升端到端多目标追踪
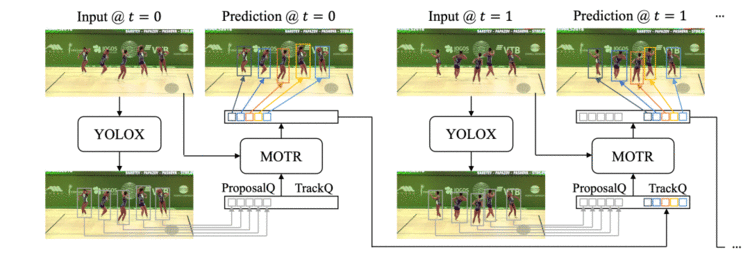
我们提出了一种简单而有效的多目标跟踪方法MOTRv2,可以使用预训练的目标检测器来提高跟踪性能。相对于现有的端到端方法,MOTRv2采用额外的目标检测器来生成锚框,为多目标跟踪方法MOTR提供了检测的先验信息,从而极大地缓解了MOTR中联合学习检测和追踪两个任务时的冲突。该方法在基准数据集MOT17、MOT20中表现良好,取得了DanceTrack挑战赛冠军(73.4% HOTA),并在BDD100K数据集上达到了最先进的性能。
👉关键词:多目标跟踪、端到端、目标检测、DanceTrack比赛
https://arxiv.org/abs/2211.09791
05
Referring Multi-Object Tracking
文本引导的多目标追踪:一个数据集benchmark,一个简单的baseline

以往的多目标追踪任务往往要求检测到可视范围内的所有目标并加以追踪,而本文提出了一个更加灵活的基于文本引导的多目标追踪任务(RMOT)。该任务可以根据人类语言指令检测和追踪特定的目标群,可以是一个目标,也可以是多个目标。本文首先构建了第一个RMOT数据集,包括公开数据集KITTI中的18个视频和人工标记的818条指令。同时,本文在MOTR的基础上提出了一个简单的端到端的RMOT基准算法,即TransRMOT。
👉关键词:多目标追踪、RMOT数据集、端到端算法
https://arxiv.org/abs/2303.03366
06
Boosting Semi-Supervised Learning by Exploiting All Unlabeled Data
提升半监督学习中低置信度样本的利用率
半监督学习(SSL)凭借着无需大规模标注数据的优势备受研究人员的关注。以FixMatch为代表的SSL算法,通过将伪标签和一致性正则化两种技术统一到一个框架中实现了目前的最优性能。在本文中,我们指出了FixMatch系列方法存在无标签数据利用率不足的缺点。针对此,我们提出了EML和ANL两个策略,用来挑选出更多的伪标签同时引入额外的标签来充分利用低置信度样本。实验表明,我们的方法可以显著提升FixMatch系列方法的精度。
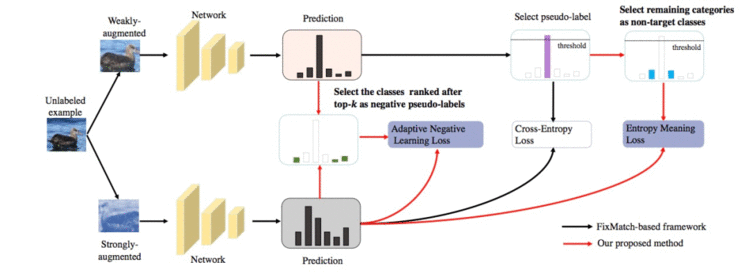
👉关键词:半监督学习、图像分类
07
Understanding Masked Image Modeling via Learning Occlusion Invariant Feature
从学习遮挡不变性的视角理解掩码图像建模
掩码图像建模(masked image modeling, MIM) 近期在自监督预训练任务上取得巨大成功,但如何理解基于重建框架的 MIM 仍是未解决的问题。本文从 MIM 隐式建模遮挡不变性的新视角,将 MIM 从单塔模型松弛为双塔模型 ,从而将 MIM 与对比学习等基于双塔的方法划归到统一的框架中。在这个统一的视角下,MIM 与对比学习的区别仅有数据变换(需要学习的不变性)与相似性度量。我们发现,基于遮挡的数据变换对于模型的重要性要大于相似性度量,而且这种遮挡不变性由框架而不是数据习得:仅用一张图像迭代5000次就能使 MIM 学到不错的特征,即使这些特征缺乏丰富的语义性,它对于识别任务而言依然是很好的初始化。
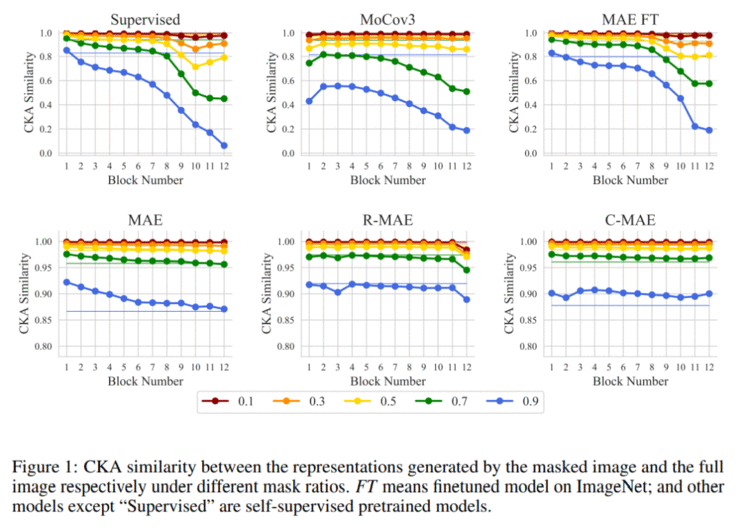
👉关键词:遮挡不变性、掩码图像建模
https://arxiv.org/abs/2208.04164
08
Differentiable Architecture Search with Random Features
基于随机特征的可微分神经网络架构搜索
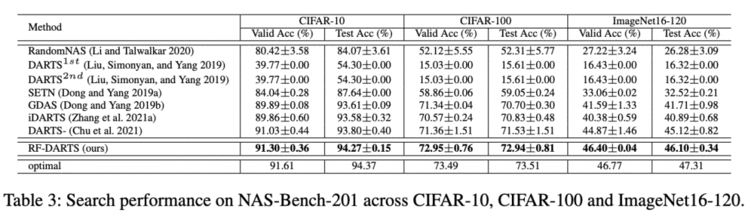
旷视研究院是最早一批进入神经架构搜索领域的机构,一直致力于发掘“本质”有效的算法。在前作《基于随机标签的可微分神经网络架构搜索》的基础上,我们进一步“删繁就简”,仅通过训练超网络中的批归一化层(BatchNorm)就可以在NAS-Bench-201上找到几乎最优的网络架构,进一步揭示了可微分神经网络架构搜索的本质是寻找“最适合优化”的网络结构。在实验中,我们以极小的搜索开销,在CIFAR、ImageNet等多个数据集上取得了最好的效果。
👉关键词:可微分神经网络架构搜索、随机特征、优化理论
https://arxiv.org/abs/2208.08835
09
Scaling up Kernels in 3D Sparse CNNs
大卷积核3D CNN
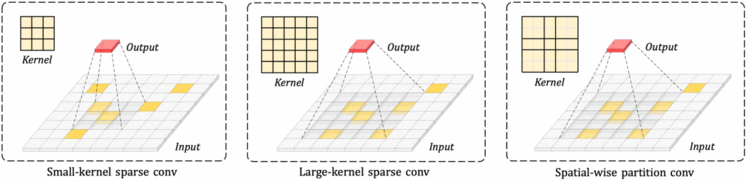
大卷积核已经在2D 图像处理领域被证明了有效性,然而在3D 领域还没有得到有效探索。其难点在于3D CNN的计算量和参数量会随着其卷积核的增加而成立方次的增加。为了解决这样的问题,我们提出了一种以空间为单位的卷积核分组,能够有效地降低大卷积核 3D CNN的计算量和优化难度。我们提出的大卷积核3D CNN在3D 点云分割、3D 点云检测任务上都取得了很大的提升,并在nuScenes LIDAR检测榜单上排名第一。
👉关键词:大卷积核、nuScenes 3D点云检测SOTA
https://arxiv.org/abs/2206.10555
10
UniDistill: A Universal Cross-Modality Knowledge Distillation Framework for 3D Object Detection in Bird’s-Eye View
统一的蒸馏框架:基于BEV域的3D检测跨模态知识蒸馏框架
在面向自动驾驶的 3D 目标检测任务中,包括多模态和单模态的传感器组合是多样和复杂的。多模态方法具有系统复杂性,而单模态方法的精度相对较低,因此如何在它们之间进行权衡是很困难的。在这项工作中,我们提出了一个通用的跨模态知识提取框架(UniDistill)来提高单模态检测器的性能。具体而言,UniDistill 将教师和学生检测器的特征投影到鸟瞰图(BEV)空间中,这是对不同模态的友好表示。然后,计算三个蒸馏损失,以稀疏地对齐前景特征,帮助学生检测器向教师检测器学习,而不会在推理过程中引入额外成本。UniDistill 可轻松支持激光雷达到摄像机、摄像机到激光雷达、融合到激光雷达以及融合到摄像机的蒸馏路径。此外,三种蒸馏损失可以过滤背景信息不对齐的影响,并在不同大小的物体之间保持平衡,从而提高蒸馏效率。在 nuScenes 数据集上的大量实验表明,UniDistill 有效地将学生检测器的 mAP 和 NDS 提高了 2.0%~3.2%。
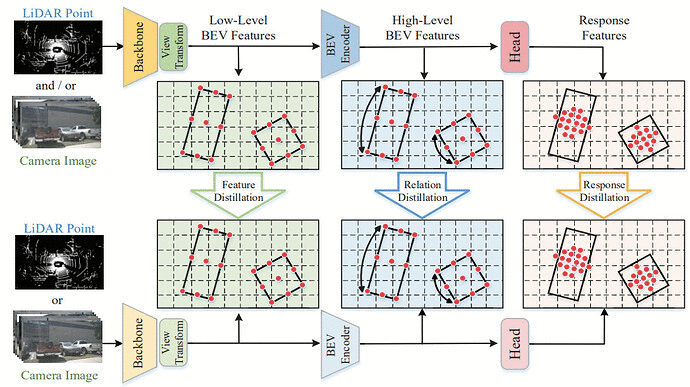
👉关键词:3D 目标检测、知识蒸馏、BEV
https://openreview.net/pdf?id=iWiuqQu8rw
11
Understanding Imbalanced Semantic Segmentation Through Neural Collapse
从神经坍缩的视角理解非平衡类别的语义分割任务
最近研究表明网络学习会有神经坍塌(Neural Collaspe)的现象:同类特征的类内均值和分类器各个类别对应的权重向量,在分类训练的最终阶段,以上两者会收敛到等角单纯形的紧框架顶点(simplex equiangular tight frame)。 在本文中,我们探索了在语义分割任务中最后一层特征中心和分类器的相应结构。 基于我们的实证和理论分析,我们指出语义分割任务本身会涉及到上下文相关性(contextual correlation)和类别间的不平衡分布,这打破了特征中心和分类器神经崩溃的等角和最大分离结构。 然而,这种等角的对称结构有利于对罕见类的区分。 为了保留这些优势,我们在特征中心空间引入了正则化器(regularizer),以促使网络在不平衡语义分割任务中学习上述对称且系统性的结构。 实验结果表明,我们的方法可以在2D图像和3D点云语义分割任务上带来都有显着改进。 此外,我们的方法在ScanNet200测试排行榜上排名第一,并创造了新的mIoU记录 (+6.8% mIoU)。
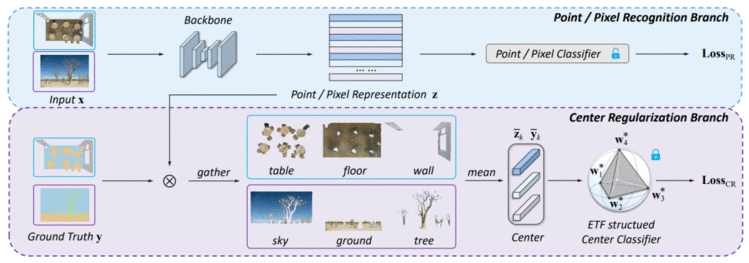
👉关键词:网络坍塌、正则器、语义分割、不平衡问题
https://arxiv.org/abs/2301.01100
12
Implicit Identity Leakage: The Stumbling Block to Improving Deepfake Detection Generalization
证明深伪检测当前研究种存在的数据分布问题,并给出可能的解决方案
深度伪造(deepfake)技术的出现带来很多社会问题,检测深度伪造生成的图片是一项当前还在进行的研究。本文关注深伪检测当前研究中普遍存在的一个问题,即研究深度伪造所用的公开数据集普遍存在对象身份泄漏的现象(Implicit Identity Leakage)使算法识别精度下降。本文提出一种缓解此现象的方法,能有效提升深伪检测任务的算法精度。
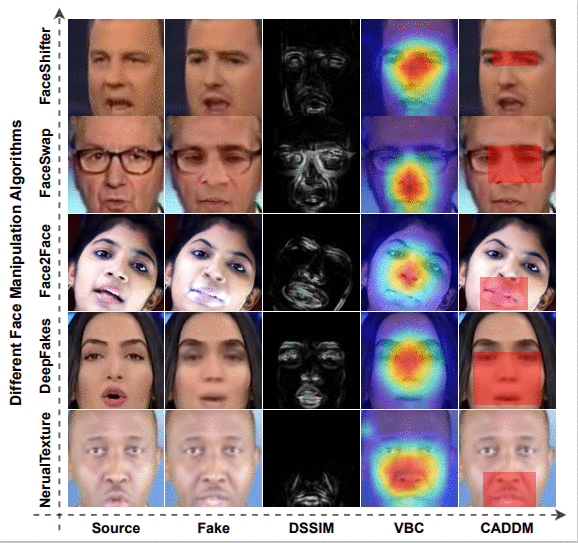
👉关键词:深伪检测
https://openreview.net/pdf?id=uSCbWUh8V_
13
Joint Token Pruning and Squeezing Towards More Aggressive Compression of Vision Transformers
推进vision transformer模型的压缩极限
Vision Transformers(ViTs)作为一种新型的网络结构在各类视觉任务表现良好,但落地仍然受其计算代价的制约。近来大家开始尝试修剪部分冗余token来获得性能和计算成本之间的trade-off;然而,修剪策略的错误难以避免,并会导致额外的上下文信息损失。为了挽救随之而来的性能下降,我们提出了一种联合令牌修剪(token pruning)和令牌挤压(token squeezing)的模块(TPS)来实现对vision transformer模型进行更高效的压缩。在保证了constant shape推理的前提下,与现有SOTA方法的比较证明,我们的方法在所有压缩强度下都优于它们:尤其是在使用更激进的压缩强度下。在将 DeiT-T&S计算代价缩减至 35% 的同时,我们与baseline相比提高了 1%-6%的准确率。我们在hybrid ViTs和vanilla ViTs上都开展了广泛的实验证明了我们方法的鲁棒性和泛用性。
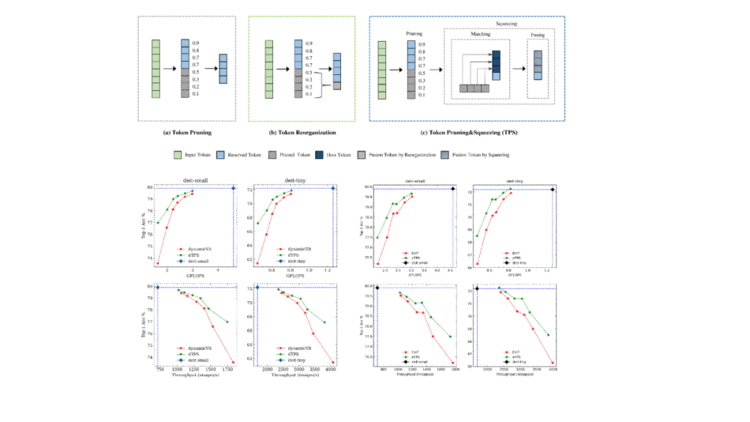
👉关键词:Vision Transformer、模型压缩、动态网络








 京公网安备 11010802041100号
京公网安备 11010802041100号